http://gcc.gnu.org/projects/cxx0x.html
Some of the features are already available in gcc.
Python Strings as Comments
The question was:
In Python we can emulate multiline comments using triple-quoted
strings, but conceptually strings and comments are very different.
I.e. strings are objects, comments are auxillary text discarded at
compile time. Strings are objects created at runtime, comments are
not.
The answer from Steven D'Aprano:
Guido's time-machine strikes again.
String literals -- not just triple-quoted strings, but any string
literal -- that don't go anywhere are discarded by the Python compiler,
precisely so they can be used as comments.
In Python we can emulate multiline comments using triple-quoted
strings, but conceptually strings and comments are very different.
I.e. strings are objects, comments are auxillary text discarded at
compile time. Strings are objects created at runtime, comments are
not.
The answer from Steven D'Aprano:
Guido's time-machine strikes again.
>>> import dis
>>> def test():
... x = 1
... """
... This is a triple-quote comment.
... """
... return x
...
>>> dis.dis(test)
2 0 LOAD_CONST 1 (1)
3 STORE_FAST 0 (x)
6 6 LOAD_FAST 0 (x)
9 RETURN_VALUE
String literals -- not just triple-quoted strings, but any string
literal -- that don't go anywhere are discarded by the Python compiler,
precisely so they can be used as comments.
ln explained best
At this article titled Demystifying the Natural Logarithm
His entire series of get an intuition articles on Maths is very good.
His entire series of get an intuition articles on Maths is very good.
Pell's Equation
x^2 - n y^2 = 1
(Pell's equation) which is named after the English mathematician John Pell. It was studied by Brahmagupta in the 7th century, as well as by Fermat in the 17th century.
http://en.wikipedia.org/wiki/Pell%27s_equation
(Pell's equation) which is named after the English mathematician John Pell. It was studied by Brahmagupta in the 7th century, as well as by Fermat in the 17th century.
http://en.wikipedia.org/wiki/Pell%27s_equation
8 Bit Byte
Factors behind the ubiquity of the eight bit byte include the popularity of the IBM System/360 architecture, introduced in the 1960s, and the 8-bit microprocessors, introduced in the 1970s. The term octet unambiguously specifies an eight-bit byte (such as in protocol definitions, for example)
http://en.wikipedia.org/wiki/Byte
Otherwise, people have tried with 12 bit byte. Varying byte length in PDP 10. 6, 7 and 9 bits in Univac computers.
http://en.wikipedia.org/wiki/Byte
Otherwise, people have tried with 12 bit byte. Varying byte length in PDP 10. 6, 7 and 9 bits in Univac computers.
Brainfuck
+++ +++ +++ +[>
+++ +++ +
>
+++ +++ +++ +
<++ .
>+++ ++ .
Brainfuck is easy and interesting.
We work on cells, like if you know c, cell is like ptr = unsigned char *
+ stands for increment like ++*ptr
- stands for decrement like --*ptr
> goes one cell right like ++ptr
< goes one cell left like --ptr
. spits out output like putchar(*ptr)
, expects input. like *ptr = getchar(stdin)
[ is the start of while block test condition (for non-zero) which is like while(*ptr) {
] is the end of the block }
And everything else is comment, like the these sentences.
The above program is designed to output "Hi" and if you include these
sentenses too, it will print "Hii" and wait for some input and enter
presses till the cell becomes zero.
Isn't it cool? :)
BTW, you can run this program using an interpretor called (bf) just an apt-get away.
+++ +++ +
>
+++ +++ +++ +
<++ .
>+++ ++ .
Brainfuck is easy and interesting.
We work on cells, like if you know c, cell is like ptr = unsigned char *
+ stands for increment like ++*ptr
- stands for decrement like --*ptr
> goes one cell right like ++ptr
< goes one cell left like --ptr
. spits out output like putchar(*ptr)
, expects input. like *ptr = getchar(stdin)
[ is the start of while block test condition (for non-zero) which is like while(*ptr) {
] is the end of the block }
And everything else is comment, like the these sentences.
The above program is designed to output "Hi" and if you include these
sentenses too, it will print "Hii" and wait for some input and enter
presses till the cell becomes zero.
Isn't it cool? :)
BTW, you can run this program using an interpretor called (bf) just an apt-get away.
Kavka's toxin puzzle
In its original form, it is:
An eccentric billionaire places before you a vial of toxin that, if you drink it, will make you painfully ill for a day, but will not threaten your life or have any lasting effects. The billionaire will pay you one million dollars tomorrow morning if, at midnight tonight, you intend to drink the toxin tomorrow afternoon. He emphasizes that you need not drink the toxin to receive the money; in fact, the money will already be in your bank account hours before the time for drinking it arrives, if you succeed. All you have to do is. . . intend at midnight tonight to drink the stuff tomorrow afternoon. You are perfectly free to change your mind after receiving the money and not drink the toxin.
Kavka's theory is that, one cannot intend to do something which one won't do.
There is an analysis of payoffs from different scenarios and the real-world example of this puzzle is:
...the Political Manifesto. Before an election, a political party will release a written document outlining their policies and plans should they win office. Many of these promises may be difficult or impossible to implement in practice. Having won, the party is not obligated to follow the manifesto even if they would have lost without it.
An eccentric billionaire places before you a vial of toxin that, if you drink it, will make you painfully ill for a day, but will not threaten your life or have any lasting effects. The billionaire will pay you one million dollars tomorrow morning if, at midnight tonight, you intend to drink the toxin tomorrow afternoon. He emphasizes that you need not drink the toxin to receive the money; in fact, the money will already be in your bank account hours before the time for drinking it arrives, if you succeed. All you have to do is. . . intend at midnight tonight to drink the stuff tomorrow afternoon. You are perfectly free to change your mind after receiving the money and not drink the toxin.
Kavka's theory is that, one cannot intend to do something which one won't do.
There is an analysis of payoffs from different scenarios and the real-world example of this puzzle is:
...the Political Manifesto. Before an election, a political party will release a written document outlining their policies and plans should they win office. Many of these promises may be difficult or impossible to implement in practice. Having won, the party is not obligated to follow the manifesto even if they would have lost without it.
X Window joke
X window: The ultimate bottleneck. Flawed beyond belief. The only thing you have to fear. Somewhere between chaos and insanity. On autopilot to oblivion. The joke that kills. A disgrace you can be proud of. A mistake carried out to perfection. Belongs more to the problem set than the solution set. To err is X windows. Ignorance is our most important resource. Complex nonsolutions to simple nonproblems. Built to fall apart. Nullifying centuries of progress. Falling to new depths of inefficiency. The last thing you need. The defacto substandard. Elevating brain damage to an art form. X window.
Password-less root shell in ubuntu
If you forgot you password for your ubuntu system you can recover using the following steps
1. Turn your computer on.
2. Press ESC at the grub prompt.
3. Press e for edit.
4. Highlight the line that begins kernel ………, press e
5. Go to the very end of the line, add rw init=/bin/bash
6. Press enter, then press b to boot your system.
7. Your system will boot up to a passwordless root shell.
Source
1. Turn your computer on.
2. Press ESC at the grub prompt.
3. Press e for edit.
4. Highlight the line that begins kernel ………, press e
5. Go to the very end of the line, add rw init=/bin/bash
6. Press enter, then press b to boot your system.
7. Your system will boot up to a passwordless root shell.
Source
Signature in Evolution
You can have evolution to execute a script as your signature. I had set it so, but whatever I do:
Resulted in something like this:
Finally figured out with the help of this post(thanks man!), that evolution is actually storing every compose action as HTML so
I would need to wrap it in HTML the output of my script to make it a legible signature.
#!/usr/bin/sh
echo "-- "
echo "Senthil"
exec fortune -s
Resulted in something like this:
-- Senthil BOFH excuse #261: The Usenet news is out of date
Finally figured out with the help of this post(thanks man!), that evolution is actually storing every compose action as HTML so
I would need to wrap it in HTML the output of my script to make it a legible signature.
_GLOBAL_DEFAULT_TIMEOUT in socket.py
In python 2.6, the timeout attribute of the socket from various higher level modules (like urllib2) is passed as socket._GLOBAL_DEFAULT_TIMEOUT.
If you look at socket.py in Lib, you will find that
a) This kind of a construct was new to me, why should _GLOBAL_DEFAULT_TIMEOUT be set to an object() than say None.
Update: Because None for a timeout is a special value that would set the socket in blocking mode. That is the reason None is not used.
b) If this is just for a global value holding, why not just
Here is my understanding, the reason for having _GLOBAL_DEFAULT_TIMEOUT is to have a global default timeout value that can be accessible via various application layer modules (like ftplib, httplib, urllib).
Update: Correct
But the default value of the timeout is written at the lower layer socket module and is returned by
Update: So what?. Wrong.
Get socket.getdefaulttimeout() is implemented in C; and to be preserve the value between C methods and the python library methods, an object() would be essential instead of a global.
object() might essentially provide an address location for the variable which would be global.
Am I confused? The way the C implementation works is the value is set to a global variable inside of C and its accessed by interfaces like getdefaulttime and setdefaulttime.
Nothing to maintain global values between Python and modules written in C. Are they sharable? I dont know.
This kind of construct is used to have a object to maintain a global state.
global myobj is just a declaration to the compiler that it is global. declared somewhere else and start using the same value. It is not setting things or even defining for the myobj to be used as global. OKay?
So, in effect:
_GLOBAL_DEFAULT_TIMEOUT = object() is a just creating a empty object whose value can be shared.
Thats it and None is not a good option because, None in this case means that socket be a blocking one.
Here are some experimentations with urllib2 and new socket._GLOBAL_DEFAULT_TIMEOUT
If you look at socket.py in Lib, you will find that
_GLOBAL_DEFAULT_TIMEOUT = object()
a) This kind of a construct was new to me, why should _GLOBAL_DEFAULT_TIMEOUT be set to an object() than say None.
Update: Because None for a timeout is a special value that would set the socket in blocking mode. That is the reason None is not used.
b) If this is just for a global value holding, why not just
global _GLOBAL_DEFAULT_TIMEOUT
Here is my understanding, the reason for having _GLOBAL_DEFAULT_TIMEOUT is to have a global default timeout value that can be accessible via various application layer modules (like ftplib, httplib, urllib).
Update: Correct
socket.getdefaulttimeout()and may be set via socket.setdefaulttimeout or via timeout parameters at the application opening functions (like urllib2.urlopen('url',timeout=42).
Update: So what?. Wrong.
Get socket.getdefaulttimeout() is implemented in C; and to be preserve the value between C methods and the python library methods, an object() would be essential instead of a global.
object() might essentially provide an address location for the variable which would be global.
Am I confused? The way the C implementation works is the value is set to a global variable inside of C and its accessed by interfaces like getdefaulttime and setdefaulttime.
Nothing to maintain global values between Python and modules written in C. Are they sharable? I dont know.
This kind of construct is used to have a object to maintain a global state.
global myobj is just a declaration to the compiler that it is global. declared somewhere else and start using the same value. It is not setting things or even defining for the myobj to be used as global. OKay?
a = 100
print id(a)
def foo():
global a
print a, id(a)
foo()
[12:17:45 senthil]$python a1.py
23379248
100 23379248
So, in effect:
_GLOBAL_DEFAULT_TIMEOUT = object() is a just creating a empty object whose value can be shared.
Thats it and None is not a good option because, None in this case means that socket be a blocking one.
Here are some experimentations with urllib2 and new socket._GLOBAL_DEFAULT_TIMEOUT
Python 2.7a0 (trunk:72879M, May 24 2009, 12:51:19)
[GCC 4.3.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import socket
>>> print socket.getdefaulttimeout()
None
>>> socket.setdefaulttimeout(42)
>>> print socket.getdefaulttimeout()
42.0
>>> import urllib2
>>> obj = urllib2.urlopen("http://www.google.com")
>>> dir(obj)
['__doc__', '__init__', '__iter__', '__module__', '__repr__', 'close', 'code', 'fileno', 'fp', 'getcode', 'geturl', 'headers', 'info', 'msg', 'next', 'read', 'readline', 'readlines', 'url']
>>> dir(obj.fp)
['__class__', '__del__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '_close', '_getclosed', '_rbuf', '_rbufsize', '_sock', '_wbuf', '_wbuf_len', '_wbufsize', 'bufsize', 'close', 'closed', 'default_bufsize', 'fileno', 'flush', 'mode', 'name', 'next', 'read', 'readline', 'readlines', 'softspace', 'write', 'writelines']
>>> dir(obj.fp._sock)
['__doc__', '__init__', '__module__', '_check_close', '_method', '_read_chunked', '_read_status', '_safe_read', 'begin', 'chunk_left', 'chunked', 'close', 'debuglevel', 'fp', 'getheader', 'getheaders', 'isclosed', 'length', 'msg', 'read', 'reason', 'recv', 'status', 'strict', 'version', 'will_close']
>>> dir(obj.fp._sock.fp)
['__class__', '__del__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '_close', '_getclosed', '_rbuf', '_rbufsize', '_sock', '_wbuf', '_wbuf_len', '_wbufsize', 'bufsize', 'close', 'closed', 'default_bufsize', 'fileno', 'flush', 'mode', 'name', 'next', 'read', 'readline', 'readlines', 'softspace', 'write', 'writelines']
>>> dir(obj.fp._sock.fp._sock)
['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'accept', 'bind', 'close', 'connect', 'connect_ex', 'dup', 'family', 'fileno', 'getpeername', 'getsockname', 'getsockopt', 'gettimeout', 'listen', 'makefile', 'proto', 'recv', 'recv_into', 'recvfrom', 'recvfrom_into', 'send', 'sendall', 'sendto', 'setblocking', 'setsockopt', 'settimeout', 'shutdown', 'timeout', 'type']
>>> dir(obj.fp._sock.fp._sock.gettimeout)
['__call__', '__class__', '__cmp__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__self__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
>>> print(obj.fp._sock.fp._sock.gettimeout)
>>> print(obj.fp._sock.fp._sock.gettimeout())
42.0
Redirect business again
.htaccess file has
But still when I do:
>>>obj = urllib2.urlopen("http://localhost/index.html")
>>>print obj.code()
200
>>>
Funny, what am I doing and why am I getting it this way? Figuring that out. Because the direct is happening transparently, one is not able to capture the redirect code.
If one needs to the capture redirect code, here is how it is done.
And the output from the session will be:
Redirect 302 /index.html "http://localhost/new file.html"
But still when I do:
>>>obj = urllib2.urlopen("http://localhost/index.html")
>>>print obj.code()
200
>>>
Funny, what am I doing and why am I getting it this way? Figuring that out. Because the direct is happening transparently, one is not able to capture the redirect code.
If one needs to the capture redirect code, here is how it is done.
import urllib2
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_302(self, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(self, req, fp,code, msg,headers)
result.status = code
return result
request = urllib2.Request("http://localhost/index.html")
opener = urllib2.build_opener(SmartRedirectHandler())
obj = opener.open(request)
print 'I capture the http redirect code:', obj.status
print 'Its been redirected to:', obj.url
And the output from the session will be:
[06:59:14 senthil]$python smartredirecthandler.py
I capture the http redirect code: 302
Its been redirected to: http://localhost/new%20file.html
The pasta theory of design
The pasta theory of design:
* Spaghetti: each piece of code interacts with every other piece of code [can be implemented with GOTO, functions, objects]
* Lasagna: code has carefully designed layers. Each layer is, in theory independent. However low-level layers usually cannot be used easily, and high-level layers depend on low-level layers.
* Ravioli: each part of the code is useful by itself. There is a thin layer of interfaces between various parts [the sauce]. Each part can be usefully be used elsewhere.
* ...but sometimes, the user just wants to order "Ravioli", so one coarse-grain easily definable layer of abstraction on top of it all can be useful.
An application design using Twisted's Aspect Oriented Programming Design is that special Ravioli.
http://twistedmatrix.com/projects/core/documentation/howto/tutorial/library.html
* Spaghetti: each piece of code interacts with every other piece of code [can be implemented with GOTO, functions, objects]
* Lasagna: code has carefully designed layers. Each layer is, in theory independent. However low-level layers usually cannot be used easily, and high-level layers depend on low-level layers.
* Ravioli: each part of the code is useful by itself. There is a thin layer of interfaces between various parts [the sauce]. Each part can be usefully be used elsewhere.
* ...but sometimes, the user just wants to order "Ravioli", so one coarse-grain easily definable layer of abstraction on top of it all can be useful.
An application design using Twisted's Aspect Oriented Programming Design is that special Ravioli.
http://twistedmatrix.com/projects/core/documentation/howto/tutorial/library.html
Dismal Google Search
Every technical query returns, results from:
www.daniweb.com/forums/thread97401.html
www.daniweb.com/forums/thread110548.html
www.gidforums.com/t-3560.html
www.velocityreviews.com/forums/t280081-floating-point-exception.html
And those pages are invariably filled with advertisements and and sometimes asks me to register to view the result too. I am dismayed, either got to have custom google search to exclude these or try other search engine.
www.daniweb.com/forums/thread97401.html
www.daniweb.com/forums/thread110548.html
www.gidforums.com/t-3560.html
www.velocityreviews.com/forums/t280081-floating-point-exception.html
And those pages are invariably filled with advertisements and and sometimes asks me to register to view the result too. I am dismayed, either got to have custom google search to exclude these or try other search engine.
All your (http,https) traffic belongs to squid
phoe6: hello, I have setup a squid proxy running at port 3128; I want all my HTTP as well as HTTPS to proxy to through this one only. what should I do? (the tutorials are too wide and I think I am impatient too :( )
rob0: um, hire someone to do it for you?
phoe6: :) well, it is just two lines rob0. :) I am trying it out.,
phoe6: Sorry, if I sounded offending with the question. Let me try it and ask specific quesitons.
rob0: np, that is how to do it: try things, read manuals, ask specific questions when you get stuck.
phoe6: well I just had to write a filter rule to accept packets through squid-user and any traffic to port 80, pot 443 to reject. by this way my browsing is through squid proxy only.
Helpful entry: http://stuvel.eu/transproxy
rob0: um, hire someone to do it for you?
phoe6: :) well, it is just two lines rob0. :) I am trying it out.,
phoe6: Sorry, if I sounded offending with the question. Let me try it and ask specific quesitons.
rob0: np, that is how to do it: try things, read manuals, ask specific questions when you get stuck.
phoe6: well I just had to write a filter rule to accept packets through squid-user and any traffic to port 80, pot 443 to reject. by this way my browsing is through squid proxy only.
$iptables -t filter -A OUTPUT -m owner --uid-owner 13 -j ACCEPT
$iptables -t filter -A OUTPUT -p tcp --dport 80 -j REJECT
$iptables -t filter -A OUTPUT -p tcp --dport 443 -j REJECT
Helpful entry: http://stuvel.eu/transproxy
Manually removing a corruped .deb install
I was getting this error, on a corruped install of a debian package.
""The package 'printers-bangalore' is in an inconsistent state and needs to be reinstalled, but no archive can be found for it. Please reinstall the package manually or remove it from the system"
To solve this issue, I followed these steps.
1) I edited /var/lib/dpkg/status and remove all references of that package. (Note that this is a tricky step; in my case it was simple)
2) sudo dpkg --configure -a
""The package 'printers-bangalore' is in an inconsistent state and needs to be reinstalled, but no archive can be found for it. Please reinstall the package manually or remove it from the system"
To solve this issue, I followed these steps.
1) I edited /var/lib/dpkg/status and remove all references of that package. (Note that this is a tricky step; in my case it was simple)
2) sudo dpkg --configure -a
World's longest domain name
Some Trivia. I liked the pi value domain name.
BTW, it goes like this:
1) Each domain name can be maximum upto 63 octets. (Octets is 8bits; can safely be considered 1 English Character).
2) The sub-division of domains like (cs.univ.edu;math.univ.edu) can go upto 127 levels.
3) But the entire domain name may not exceed 253 octets.
So, if we are to search for the longest domain name (including sub-domains), we will end up with 253 english character long string. ( That would be like a page of characters). :)
BTW, it goes like this:
1) Each domain name can be maximum upto 63 octets. (Octets is 8bits; can safely be considered 1 English Character).
2) The sub-division of domains like (cs.univ.edu;math.univ.edu) can go upto 127 levels.
3) But the entire domain name may not exceed 253 octets.
So, if we are to search for the longest domain name (including sub-domains), we will end up with 253 english character long string. ( That would be like a page of characters). :)
Upgraded Ubuntu from 8.10 to 9.04
This was on my Thinkpad T400 laptop, where Ubuntu is installed through Wubi.
After upgrade, X could not start. No GUI No Window Manager.
Followed the steps mentioned here.
The problem was with fglrx driver.
1) Go to Recovery mode during boot.
2) Choose to drop into Shell with networking support
and do
Reboot. It started working for me.
First thing you will notice in 9.04 is the notification system it has. Nice eye candy stuff.
After upgrade, X could not start. No GUI No Window Manager.
Followed the steps mentioned here.
The problem was with fglrx driver.
1) Go to Recovery mode during boot.
2) Choose to drop into Shell with networking support
and do
sudo apt-get remove xorg-driver-fglrx
Reboot. It started working for me.
First thing you will notice in 9.04 is the notification system it has. Nice eye candy stuff.
Upgraded to Ubuntu 8.10 from 8.04
Used the Update Manager from the System-> Administration menu.
* Attempts to update through Indian Servers failed.
* There were constant interview dialogues. I got to look out for a configuration file, which can provide an interrupted/quiet upgrade.
* Attempts to update through Indian Servers failed.
* There were constant interview dialogues. I got to look out for a configuration file, which can provide an interrupted/quiet upgrade.
Setting up http redirect
I was trying to setup a http redirect on ubuntu. Spent quite some time.
1) Ubuntu has a
Only this step will enable you to use .htaccess file.
2) In the .htaccess file, I was doing
Spent more than a hour to figure out, why the redirect is not happening. The problem was, I was doing
1) Ubuntu has a
/etc/apache2/sites-available/defaultfile where you will have to change the AllowOverride option from None to All.
Only this step will enable you to use .htaccess file.
2) In the .htaccess file, I was doing
Redirect 302 ./index.html http://localhost/new.html
Spent more than a hour to figure out, why the redirect is not happening. The problem was, I was doing
./index.htmlinstead of just
/index.html
Bytes and String in Py3k
Martin's Explaination:
It's really very similar to 2.x: the "bytes" type is to used in all
interfaces that operate on byte sequences that may or may not represent characters; in particular, for interface where the operating system deliberately uses bytes - ie. low-level file IO and socket IO; also for cases where the encoding is embedded in the stream that still needs to be processed (e.g. XML parsing).
(Unicode) strings should be used where the data is truly text by
nature, i.e. where no encoding information is necessary to find out
what characters are intended. It's used on interfaces where the
encoding is known (e.g. text IO, where the encoding is specified
on opening, XML parser results, with the declared encoding, and
GUI libraries, which naturally expect text).
- base64.encodestring expects bytes (naturally, since it is supposed to
encode arbitrary binary data), and produces bytes (debatably)
- binascii.b2a_hex likewise (expect and produce bytes)
- pickle.dumps produces bytes (uniformly, both for binary and text
pickles)
- marshal.dumps likewise
- email.message.Message().as_string produces a (unicode) string
(see Barry's recent thread on whether that's a good thing; the
email package hasn't been fully ported to 3k, either)
- the XML libraries (continue to) parse bytes, and produce
Unicode strings
- for the IO libraries, see above
It's really very similar to 2.x: the "bytes" type is to used in all
interfaces that operate on byte sequences that may or may not represent characters; in particular, for interface where the operating system deliberately uses bytes - ie. low-level file IO and socket IO; also for cases where the encoding is embedded in the stream that still needs to be processed (e.g. XML parsing).
(Unicode) strings should be used where the data is truly text by
nature, i.e. where no encoding information is necessary to find out
what characters are intended. It's used on interfaces where the
encoding is known (e.g. text IO, where the encoding is specified
on opening, XML parser results, with the declared encoding, and
GUI libraries, which naturally expect text).
- base64.encodestring expects bytes (naturally, since it is supposed to
encode arbitrary binary data), and produces bytes (debatably)
- binascii.b2a_hex likewise (expect and produce bytes)
- pickle.dumps produces bytes (uniformly, both for binary and text
pickles)
- marshal.dumps likewise
- email.message.Message().as_string produces a (unicode) string
(see Barry's recent thread on whether that's a good thing; the
email package hasn't been fully ported to 3k, either)
- the XML libraries (continue to) parse bytes, and produce
Unicode strings
- for the IO libraries, see above
Does parse_header really belong to cgi?
http://bugs.python.org/issue3609
Barry's thought is it can be moved to email module.
Simple CGIHTTPServer and Client in Python 3k
Python 3k - CGIHTTPRequestHandler example.
Run this server.
Create a Directory 'cgi' in the directory you have the above server script and place the following python cgi code.
filename: test.py
Open the Browser and point to http://localhost:8000/cgi/test.py
import http.server
import http.server
class Handler(http.server.CGIHTTPRequestHandler):
cgi_directories = ["/cgi"]
server = http.server.HTTPServer(("",8000),Handler)
server.serve_forever()
Run this server.
Create a Directory 'cgi' in the directory you have the above server script and place the following python cgi code.
filename: test.py
#!/usr/local/bin/python3.1
import cgitb;cgitb.enable()
print("Content-type: text/html")
print()
print("<title>CGI 101</title>")
print("<h1>First CGI Example</h1>")
print("<p>Hello, CGI World!</p>")
Open the Browser and point to http://localhost:8000/cgi/test.py
file opening modes.
Possible values for the mode open are
"r" or "rt"
Open for reading in text mode.
"w" or "wt"
Open for writing in text mode.
"a" or "at"
Open for appending in text mode.
"rb"
Open for reading in binary mode.
"wb"
Open for writing in binary mode.
"ab"
Open for appending in binary mode.
"r+", "r+b"
Open for reading and writing.
"w+", "w+b"
Open for reading and writing, truncating file initially.
"a+", "a+b"
Open for reading and appending.
"r" or "rt"
Open for reading in text mode.
"w" or "wt"
Open for writing in text mode.
"a" or "at"
Open for appending in text mode.
"rb"
Open for reading in binary mode.
"wb"
Open for writing in binary mode.
"ab"
Open for appending in binary mode.
"r+", "r+b"
Open for reading and writing.
"w+", "w+b"
Open for reading and writing, truncating file initially.
"a+", "a+b"
Open for reading and appending.
Yahoo Hack Day India 2009
I developed an application using Y! BOSS Search APIs, Linguistics, Machine Learning and Google App engine.
Here is the Application Live. Use it anytime:
Here is the Source code for the Project:
Here is the Application Live. Use it anytime:
Here is the Source code for the Project:
unix_time_1234567890
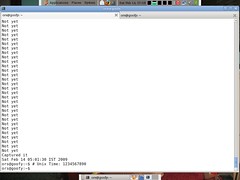
unix_time_1234567890
This was fun. I could manage to capture it again. This time it was with Vijay.
Previously, while at Dell, along with another friend, Raj, had captured 1111111111.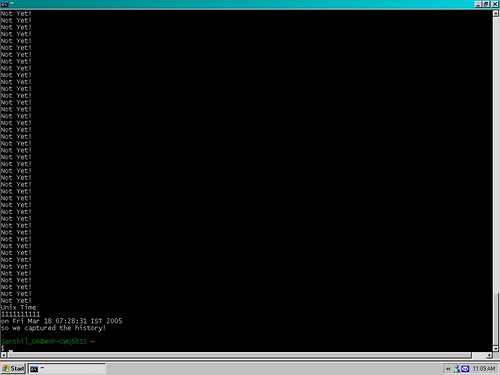
Sent Form 8233
For the PyCon Tutorial Compenstation.
I request you to print the attached PDF. Complete the Necessary
details (lower half) from PSF and please FAX
a) My Form 8233 with PSF details.
b) PSF Authorization Letter.
To my FAX Number: 91 80 30501090.
Bug-queue - http.client.HTTPMessage.getallmatchingheaders() always returns []
> Further investigation ( grep -r getallmatchingheaders Lib/* ) reveals
> that in addition to having no tests, and being implemented incorrectly
> in http.client, getallmatchingheaders() is called only once, in
> http.server; that code is also broken (I reported this yesterday in
> #5053).
>
> Maybe Python 3 is where getallmatchingheaders can make a graceful
> goodbye (and a 2to3 conversion added?).
>
> Python tracker http://bugs.python.org/issue5053
> that in addition to having no tests, and being implemented incorrectly
> in http.client, getallmatchingheaders() is called only once, in
> http.server; that code is also broken (I reported this yesterday in
> #5053).
>
> Maybe Python 3 is where getallmatchingheaders can make a graceful
> goodbye (and a 2to3 conversion added?).
>
> Python tracker http://bugs.python.org/issue5053
PyCon Tax information
On a go forward basis, we are taking the position that the PSF won't issue tutorial payments without a W-9 for US persons (US citizen or resident alien) or an 8233 with ITIN for foreign persons (but see below).
Non-US Taxpayers
============
For non-US persons ('non-resident aliens', in the IRS lingo) we need to withhold 30% of the payment unless they are citizens of a country which
has a tax treaty with the USA which allows a lesser rate on personal service income. e.g. for Canada, UK, DE the withholding rate is currently zero. The PSF has to file a 1042-S information return (which is equivalent to a 1099) regardless; there is no lower limit on the compensation.
http://www.irs.gov/publications/p515/ar02.html NRA Withholding
http://www.irs.gov/pub/irs-pdf/p519.pdf US Tax Guide for Aliens
http://www.irs.gov/publications/p901/ar02.html Countries with treaties
To avoid withholding we need to get a Form 8233 from each presenter each year, assuming they are citizens of a treaty country.
http://www.irs.gov/pub/irs-pdf/f8233.pdf On-line Form 8233
http://www.irs.gov/instructions/i8233/ Instructions
This is very easy to complete, except that it requires an ITIN ('individual taxpayer identification number) the first time, and that is a bother:
http://www.irs.gov/pub/irs-pdf/fw7.pdf On-line Form W-7
http://www.irs.gov/taxtopics/tc857.html Instructions - short
http://www.irs.gov/pub/irs-pdf/p1915.pdf Instruction Booklet
The catch on the W-7 is the US Social Security Administration has to deny a Social Security Number application and that denial has to be provided along with the W-7. That's a separate application to the SSA.
There is an exception to this: if the tutorial presentation compensation can be considered a honorarium, then a letter from the PSF to that effect will allow
the SSA denial process to be skipped, per Exception 2a (page 25 of p1915). The PSF has discussed this with the IRS, and they agree that the tutorial
compensation can be considered an honorarium. This means that the applicant would need a letter from the PSF requesting the tutorial presentation, and the applicant would fill in 'Python Software Foundation' on line 6g as the 'company' and provide a copy of the letter along with his/her W-7 application.
So the process would be as follows, assuming the presenter doesn't already have a US ITIN:
Fax the PSF an 8233 (without an ITIN) and a fax number. The PSF will complete the lower half and FAX a copy back along with the authorizing letter. Submit a W-7 with the 8233, acceptable identification documentation (see Pub 1915, typically a certified copy of a passport), and the authorizing letter to the IRS to get the ITIN. This should take 4 - 6 weeks. Send the ITIN back to the PSF on an updated 8233. This will allow the PSF to avoid the withholding. If the presenter has no other US source income, there would be no taxes owed on amounts lower than $3300, and no 1040NR need be filed in that case.
http://www.irs.gov/localcontacts/article/0,,id=101292,00.html
Without the ITIN, the PSF is required to withhold 30%. To get it back by filing a 1040NR plus Schedule C, the presenter would need an ITIN, anyway. So
if he is a citizen of a treaty country and cares about the 30%, he should get an ITIN, send the 8233, and avoid both withholding and filing (assuming no
other US income).
The PSF will offer the option of 30% withholding if the presenter chooses not to supply the document, or cannot do so in time. The presenter could later
acquire an ITIN and file for a refund up to three years after the due date of the return. At least, that is the filing deadline for a refund on a US 1040;
the foreign filer should confirm that deadline for a 1040NR. However, it is probably simpler for all concerned to delay payment until the ITIN is
available for the 8233.
Non-US Taxpayers
============
For non-US persons ('non-resident aliens', in the IRS lingo) we need to withhold 30% of the payment unless they are citizens of a country which
has a tax treaty with the USA which allows a lesser rate on personal service income. e.g. for Canada, UK, DE the withholding rate is currently zero. The PSF has to file a 1042-S information return (which is equivalent to a 1099) regardless; there is no lower limit on the compensation.
http://www.irs.gov/publications/p515/ar02.html NRA Withholding
http://www.irs.gov/pub/irs-pdf/p519.pdf US Tax Guide for Aliens
http://www.irs.gov/publications/p901/ar02.html Countries with treaties
To avoid withholding we need to get a Form 8233 from each presenter each year, assuming they are citizens of a treaty country.
http://www.irs.gov/pub/irs-pdf/f8233.pdf On-line Form 8233
http://www.irs.gov/instructions/i8233/ Instructions
This is very easy to complete, except that it requires an ITIN ('individual taxpayer identification number) the first time, and that is a bother:
http://www.irs.gov/pub/irs-pdf/fw7.pdf On-line Form W-7
http://www.irs.gov/taxtopics/tc857.html Instructions - short
http://www.irs.gov/pub/irs-pdf/p1915.pdf Instruction Booklet
The catch on the W-7 is the US Social Security Administration has to deny a Social Security Number application and that denial has to be provided along with the W-7. That's a separate application to the SSA.
There is an exception to this: if the tutorial presentation compensation can be considered a honorarium, then a letter from the PSF to that effect will allow
the SSA denial process to be skipped, per Exception 2a (page 25 of p1915). The PSF has discussed this with the IRS, and they agree that the tutorial
compensation can be considered an honorarium. This means that the applicant would need a letter from the PSF requesting the tutorial presentation, and the applicant would fill in 'Python Software Foundation' on line 6g as the 'company' and provide a copy of the letter along with his/her W-7 application.
So the process would be as follows, assuming the presenter doesn't already have a US ITIN:
Fax the PSF an 8233 (without an ITIN) and a fax number. The PSF will complete the lower half and FAX a copy back along with the authorizing letter. Submit a W-7 with the 8233, acceptable identification documentation (see Pub 1915, typically a certified copy of a passport), and the authorizing letter to the IRS to get the ITIN. This should take 4 - 6 weeks. Send the ITIN back to the PSF on an updated 8233. This will allow the PSF to avoid the withholding. If the presenter has no other US source income, there would be no taxes owed on amounts lower than $3300, and no 1040NR need be filed in that case.
http://www.irs.gov/localcontacts/article/0,,id=101292,00.html
Without the ITIN, the PSF is required to withhold 30%. To get it back by filing a 1040NR plus Schedule C, the presenter would need an ITIN, anyway. So
if he is a citizen of a treaty country and cares about the 30%, he should get an ITIN, send the 8233, and avoid both withholding and filing (assuming no
other US income).
The PSF will offer the option of 30% withholding if the presenter chooses not to supply the document, or cannot do so in time. The presenter could later
acquire an ITIN and file for a refund up to three years after the due date of the return. At least, that is the filing deadline for a refund on a US 1040;
the foreign filer should confirm that deadline for a 1040NR. However, it is probably simpler for all concerned to delay payment until the ITIN is
available for the 8233.
Python for Haiku
This bug tracks the effort to include Python on Haiku
<http://bugs.python.org/issue4933>
I find this effort interesting as people are working to bring up an
interesting OS up again! I would try Haiku at some-point, now that
Python should be available.
<http://bugs.python.org/issue4933>
I find this effort interesting as people are working to bring up an
interesting OS up again! I would try Haiku at some-point, now that
Python should be available.
My musts for an OS are:
1) sh
2) vim
3) net
4) mutt
5) python
6) gcc
7) X Window System
8) firefox
Guido's response on supporting Python on Haiku:
>
> I'm with Martin. In these days of distributed version control systems, I
> would think that the effort for the Haiku folks to maintain a branch of
> Python in their own version control would be minimal. It is likely that
> for each new Python version that comes out, initially it is broken on
> Haiku, and then they have to go in and fix it. Doing that in their own
> version control has the advantage that they don't have to worry about
> not breaking support for any other minority operating systems, so I
> expect that all in all the cost will be less for them than if they have
> to submit these patches to core Python; and since that will definitely
> be less work for core Python, I would call that a win-win solution.
>
Py3K, what to look for in brief
This article was referenced by Guido in the Python-Dev indicating certain interests from academic community.
Actually thats a good article summarizing what to look for in Py3k.
1) Simpler built-in types.
Instead of having a built-in type for int and then for long as in Py26, have a single built-in type int in py3k, which will behave like long and serve for int as well.
2) In py26, you and str and unicode. Now Its just str, which is internally unicode. So all strings are unicode in py3k.
There is a separate bytes type for bytes of characters.
3) 1/5 will be 0.2 in Python3k. If you want the result to be 0, like in Python26, do 1//5
4) No comparisons supported between incompatible types. Documents from time immemorial advised the users to not to rely and it can change anytime. Well the change has happened.
5) its print() function for output now, just like input() function input.
Two things here. Previously in py2x, input() expected an object and raw_input() was actually used to input. Now in py3k, its just input() which will behave just like raw_input() before.
And in py2x, print was a statement, now its a function.
The article mentioned at the start gives a good rationale.
All you have do is, as soon as you type print, your fingers should automatically now get used to typing ( and proceed with what you were doing. More details on print function in py3k can be found in docs.
6) Everything is a new style class. All classes that you define will implicitly be derived from the object class.
7) There is refactoring tool developed by python hackers which can be used to port your py2x code to py3k. Everyones resounding advice is Use It!. This will help in migration as well fix any issues with the refactoring tool.
Actually thats a good article summarizing what to look for in Py3k.
1) Simpler built-in types.
Instead of having a built-in type for int and then for long as in Py26, have a single built-in type int in py3k, which will behave like long and serve for int as well.
2) In py26, you and str and unicode. Now Its just str, which is internally unicode. So all strings are unicode in py3k.
There is a separate bytes type for bytes of characters.
3) 1/5 will be 0.2 in Python3k. If you want the result to be 0, like in Python26, do 1//5
4) No comparisons supported between incompatible types. Documents from time immemorial advised the users to not to rely and it can change anytime. Well the change has happened.
5) its print() function for output now, just like input() function input.
Two things here. Previously in py2x, input() expected an object and raw_input() was actually used to input. Now in py3k, its just input() which will behave just like raw_input() before.
And in py2x, print was a statement, now its a function.
The article mentioned at the start gives a good rationale.
All you have do is, as soon as you type print, your fingers should automatically now get used to typing ( and proceed with what you were doing. More details on print function in py3k can be found in docs.
6) Everything is a new style class. All classes that you define will implicitly be derived from the object class.
7) There is refactoring tool developed by python hackers which can be used to port your py2x code to py3k. Everyones resounding advice is Use It!. This will help in migration as well fix any issues with the refactoring tool.
Subscribe to:
Posts (Atom)